将发表在中国科技核心刊物《网络新媒体技术》,与朋友陈剑博士,王艳合作
————————————————————————
任何金融活动都有风险,金融活动的核心就是在承担风险中得到相应的经济回报。由此,对于金融机构来说,风险管理是机构运营中的重点所在。而对风险的测量,则是风险管理中的核心环节。如果无法有效、准确地量度风险,即便监管流程再完全,也无法做到对风险进行有效的管理。风险的测量依赖于数据。在实际活动中,数据是风险管理体系中最重要的因素之一。可以说有了全面、准确、及时的数据,风险控制体系就成功了一半。近几十年来,金融活动在社会活动中的日益渗透和变化使得风险管理对数据的依赖和要求也日益提高。特别是近年来,随着科学技术,特别是信息收集技术以及互联网的爆发式发展,海量信息数据的产生使得金融风险管理在模式上也迫切需要改善。举例来说,40多年前,纽约大学的教授EdwardAltman曾提出一个基于企业资产负债表的量化模型Z-Score来度量企业违约风险,但由于企业运营杠杆逐渐增加、透明性的减弱、以及与政府交往的关系等因素,同时经济发展的新常态的出现等,传统的信用风险模型Z-score的应用也受到相应限制。
在常见的金融风险(市场、信用、流动性、营运)中,有着相对完善的、能够最有效应用大数据分析并进行管理的,就属于信用风险。所谓信用风险是指在商业活动中由于借款者(债务人)未能满足合同要求而给贷款者(债权人)带来经济损失的风险。由于信用风险是以借款者还款能力和还款意愿为基础,因此,计算出借款者的资产价值多少,未来现金流的大小,和还款意愿强弱是度量信用风险的关键。按照借款者类别,信用风险基本可以分为以下几类[1]:
* 大中型企业信用风险
* 小微型企业信用风险
* 个人/消费者信用风险
管理好这三类信用风险,不但是贷款商业银行,贷款者的立身基石,也是投资于固定收益债券类投资者的成败关键。对它们的分析和建模,虽然都依赖对于大量数据的整理和概括,但其方法论和实际技巧,都大相径庭。
大中型企业的信用分析,主要基于理性预期假设(Rational Expectation Hypothesis)和期权定价理论(Option Pricing Theory)。其基本前提就是:
* 企业的违约决策,是有效的,即其管理人会在违约有利的情况下理性地做出违约的决定;
* 违约的可能性及损失率,是由企业的资产、负债、波动性、利率水平、及破产成本等因素决定的,而且可以由传统的Black-Sholes-Merton期权定价模型来进行预测,具体而言:
企业的杠杆率越高,违约率也越高;
企业的波动性越大,违约率也越高;
无风险利率越高,违约率一般较低;
违约的损失率(Loss Rates),和企业的行业特性高度相关:固定资产占比越低,损失率越高。
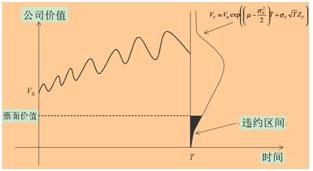
在西方,由于大中型企业可以在市场上融资,因此,企业信用等级评估是投资关注的重要指标。信用评级也主要是基于资产、债务等财务信息。不论是市场熟知的KMV的EDF模型,还是彭博的DRSK模型都是围绕企业资产价值、偿还债务能力来计算信用风险。但由于第三方信用评级机构的收入来自与信用债的发行方,因此第三方信用评级机构的公正性得到市场怀疑,特别是2008年席卷全球的金融危机更是将第三方信用评级机构推向舆论中心[2]。下图显示了EDF模型中基于数据而计算债务到期时公司价值的分布图。
对于那些还不够大,无法利用债券市场融资的中型企业,邓白氏(Dun& Bradstreet)信用分数是这些企业在银行取得贷款的重要指标。具有80年历史的邓白氏是西方商业征信市场的最主要提供商。到2012年底,邓白氏的全球信用数据已经覆盖200多个国家的2.2亿家公司。邓白氏利用通过多种方式和渠道收集的商业信息,如公司规模、历史、法律诉讼、财务信息、还款历史等来计算企业在今后12个月里破产和重组的概率以及违约的可能性(即信用风险)。
无论哪种方法,信用风险的高低是取决企业融资成本大小的关键。不管是在资本市场上融资,或者是银行直接融资,信用风险评估是贷款评审的必备程序。而评级机构,则是左右企业融资成本的关键。所以每个评级机构,都有高度专业化的量化金融团队,对企业进行风险分析、建模、和评级。一些有能力的贷款机构或投资机构也常常设立自己的量化研究团队,一方面为解决第三方评级机构对外并不公开的评级黑匣子流程,使得信用风险度量更加有把握;另一方面也是可以通过市场对信用风险的价格错配而谋求套利机会。
对于小微企业(micro business。美国富国银行定义小微企业为年收入不足2百万的企业[3]),由于缺乏资产,信用风险更多地是与企业所有人的信用和资产相挂钩。小微企业商业贷款是企业主个人贷款的延伸。富国银行小微企业商业贷款是以商业信用形式来发放。商业信用上限为3万美元。对于超过3万美元上限的贷款额度,企业必须展示出商业需求和职业经验。因此,小微企业贷款大多为信用贷。信用风险建模和个人并无太大区别。
对于消费者个人的信用风险建模,则主要基于在大样本上的计量经济建模。其基本假设就是在相同条件下,个体会与大样本中的相似个人做出相似的行为选择。比如,两个相似的消费者,拥有以下的共同特性:
相似的收入;
相似的教育程度;
相似的负债水平;
相似的信用分数;
相似的消费习惯;
其他的可量测变量
那么模型假设一般会认为两个人在同样的经济环境下,比如:
房价下跌;
失业率上升;
离婚、或其他家庭变化;
会做出相似的违约决定。当然,这只是统计意义上的相似,即观测到百分之一的对象违约,那么我们对于一个相似消费者在类似情况下违约的可能性的预测也是百分之一。模型误差,统计误差肯定是存在的,因此,保持大样本是统计模型的基本要求。以房屋按揭贷款为例,在建立违约模型的时候,经常要运用以下这类维度的大数据:
* 按揭记录:
#以千万,甚至以亿计的按揭贷款记录;
#每个按揭贷款可能有150-200个数据项,比如:
@按揭类型:包括:
贷款利率;
贷款目的(购房、再融资、提现);
固定或是浮动利率;
还本付息年限及计划;
@ 贷款人记录,包括;
信用记录/信用分数;
家庭收入及财产记录;
其他负债;
自住或投资;
@ 抵押品记录,包括:
房价;
房租收入;
房价波动性;
房产所在地;
#上十亿级别的每月还款/违约观测记录;
#每月的观测记录,包括:
还款额度;
违约与否;
累积违约金额;
预付记录,等等。
* 每月的其他相关时域变量,比如:
房价变化;
利率变化;
失业率变化,等等。
当然,收集到了这些数据,只不过是信用风险分析建模的第一步。我们还需要用于以下的计量经济学、大数据分析、计算机仿真、应用数学等技巧,比如:
* 数据清洁、整理、采样、样板数据重构;
* 模型选择、估计、校准(Model Selection/Estimation/Calibration);
* 预测及计算机模拟;
* 对于模型驱动变量的灵敏度分析。
在这儿,特别要强调一下数据的采样和清理。由于数据的体量太大,以及非结构化的特征,完全收集到调查群体的每一位、每一项数据是不可能的,而且数据的准确性也不能完全保证;更为重要的是,数据并不是越大就越好。因此,进行数据调查设计和抽取,将数据进行标准化,标签化,结构化,有利于分析的便利性和有效性。特别是对实时跟踪的一些市场动态数据,如果跟踪的数据过于庞大和复杂,则容易产生数据不一致、维度过高模型无解的、延时等问题。
在消费者金融业,商业银行及类似的大型金融机构(比如美国两房、三大评级机构、五大投资银行)已经雇佣了数以千计的经济学家、统计学家、计算机科学家及数学家们,开发了多年的基于大数据的模型,如以上所提到的按揭贷款违约模型,信用卡模型,信用评分模型。
下面我们以美国KDS公司为例。KDS是一个位于加州San Jose的金融工程公司。其主要客户为高盛、摩根斯坦利等华尔街投资公司、富国(Wells Fargo)等大型商业银行,以及资产管理公司[4](包括对冲基金)。目前,它所拥有的消费者数据达2000TB。KDS系统为金融公司提供了证券期权和期货定价、资产抵押债权、消费者预期、违约以及损失模型的风控的全面分析。随着计算机技术的发展,大数据的存储并不是问题,但是对大数据的运算却面临很大的挑战。当多维的非结构化或者半结构化数据集中在关系型数据库中时,运算、分析会耗时过长。KDS早就有了自己开发的专利(下图1)。
图1. UBX数据排序专利(美国)
图2显示其处理海量数据专利的数据排序UBX,以及UBX系统构架),利用2000多个CPU+GPU节点的计算集群,通过运用其高性能的大数据挖掘和云计算的专利平台,以及系列数学模型,如量子场论、微分几何、流行拓扑、复频域分析等,来实现对数据的特征量化,从而达到结合科学的分析、模拟、风控的最优化决策。
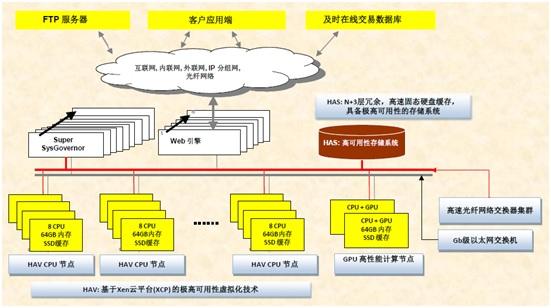
图2. UBX的系统构架
图3显示了KDS对美国按揭抵押债权的客户分析界图面。对于客户所选的每一个选项,KDS后台的计算平台利用UBX和其它特配技术给与用户即时反馈。比如,在每月第五个工作日,美国最大的按揭贷款公司,房利美、房地美、吉丽美就会向市场公布最近一个月的提前还款数据。由于两房和吉丽美控制着全美10万亿按揭资产证券化市场的90%(以2013年新发行的按揭占比计算),因此,其每月发布的数据对债券交易市场有重要意义。利用上述技术,KDS可以在25秒内计算出各种类型按揭的提前还款率,对于从事按揭债券套利的交易员来说,能在几十秒内完成以TB为基础的大数据综合分析为他们领先于竞争对手洞悉按揭市场变化,及时调整仓位和交易策略赢得了时间。
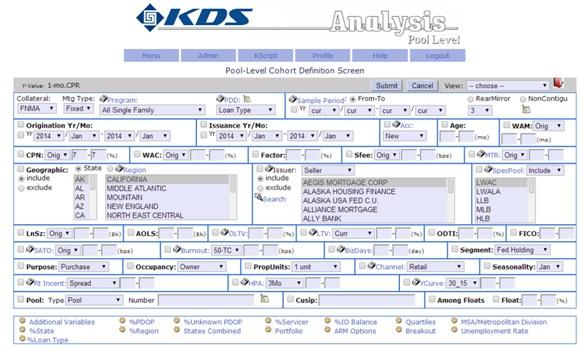
图3。KDS按揭抵押债券分析系统界面
对大数据的误解
国内现在流行大数据,好像大数据是解决信用风险的万能钥匙。这是不对的。数据是基础,开发数据才是关键。即便大数据可开发功能是如此强大,我们也不能说大数据就是万能的。比如,基于大数据估计出来的个人房屋按揭信用模型并没有帮助投资者防范席卷全球的金融危机。这是为什么呢?我们认为主要有两个基本原因:
1. 计量经济学模型(或任何基于历史数据的预测模型),都假设在相同条件下,人们会做出相同的行为选择,这通常是正确的。但在模型中没有被捕获的变量(即所谓潜在变量Latent Variable),有可能在某时某地发生改变,从而改变人们的行为。像新的抵押贷款产品,人们对拥有自有住房的看法,等等。这种影响是很难单独被传统数据抓获。而大数据的技术还也不可能产生一个系统地展现方式。同时,人、市场行为会发生突变,使得在正常情况下的常态行为模式发生转变。比如,债券和股票的关联度通常为负,这也是投资多元化的基础之一。但在危机爆发之时,如2008年,市场会在恐慌下抛弃任何证券,包括债券和股票,而转向持有现金。这时债券和股票的相关度会突然从负数变为1。传统的负相关假设不再成立。这种突发事件如何从大数据中体现,同时在短时间里改变投资仓位和投资方法还没有很好的解决方案。再比如,房贷借款者在还款违约时并不会马上卖房还债,但在经济危机下,房屋借款者同时失去工作,而社会就业环境又极度困难,在这种情况下,借款者的行为模式如何变化?当大数据中缺乏类似环境时,这种模式的变化就不甚明了。
2. 预测不仅需要模型,也需要输入,比如假设:未来的利率如何变化,房价增长率如何?但是在很多时候,没有一个好办法来事先判断假设的合理性。例如,在2007年美国房产价格巅峰之时,还假设房屋价格将持续保持长期的4.2%年增长率(当时美国房价已经保持了10年的持续高速增长),当时看上去也许是一个非常合理的假设。但现在回头来看,这个假设不但是完全没有用的,甚至是非常有害的。但为什么当时市场认为增长率将持续呢?在美国当时,大数据的应用已经是非常普遍了。但基于历史的数据,以及缺乏市场风险的传导机制的理解使得对假设的合理性缺乏判断。
随着互联网的普及,数据挖掘技术的深入,大数据分析在消费者信用风险中将会起着越来越重要的作用。但是不加分析的迷信大数据,也不科学。在消费者信用评估中,还款意愿与还款能力是基本。如果能够很好地把握贷款者的收入、债务,以及还款习惯,那么个体的信用评估就会相当准确。在这个基础上,其他数据,如个人上社交网站的频度,社交群体可信度[5],等起的作用并不大。最近国内信用大数据圈里的常常谈起美国的Zestfinance。这是一家基于大数据运用于个人信用评分的公司,成立于2009年。国内不少热衷者认为,这个公司将颠覆传统个人信用评分方式。的确,Zestfinance利用了上千个来源于不同地方的与信用相关或不相关的数据变量,从个人财务状况到对社交网站的使用量,对个人违约风险做出评估。这些数据量远远超出传统信用模型。但对于从事过个人信用模型开发的专业人士来说,Zestfinance仅仅会对传统模型有改进作用,而远远谈不上颠覆。ZestFinance创始人在最近的中国之行中也自己说道,Zestfinance服务于无信用评分或信用评分很低的小众人群,由于美国二级数据批发商极多,Zestfinance自己也很少在互联网上收集数据,基本上是通过购买得到这些基本数据。而Zestfinance所能购买的到的数据银行也可以得到,只是银行依靠自己第一手信贷数据已经能够进行对借款者的信用评估[6]。由此可见,传统的个人信用评级方法并没有被撼动,更不会被Zestfinance所颠覆。但是,Zestfiance开启了一扇大门,促使传统评级方法不但在理念上,在方式方法上也要有相应改善。因此,了解大数据并不是万能的。了解其局限性,才能更好地发挥其在金融风控中作用。
_________________
[1] 在这儿,我们跳过政府主体,包括地方债。事实上,政府在融资中同样存在信用风险问题。对政府信用分析方法与企业、个人虽然有不同,但差别并没有根本区别。
[2] 比如,在投资银行雷曼兄弟2008年9月15日倒闭前一天,穆迪、标普、惠誉三个主要第三方评级机构均给出雷曼兄弟A的评级。
[3] 美国银行业主要是根据企业人数来定义企业规模。小微企业的雇员人数低于100人。[4] 管理4万多亿美元的中国外汇管理局也是客户之一。
[5]美国历史上最大诈骗案,麦道夫骗局中,麦道夫(他本人做过纳斯达克的主席)的社交圈非贵即富。然而相信他可靠的投资者损失了600亿美元,不可谓不惨重。
[6] 如我们在上文中所说,个人信用风险取决于还款能力与还款意愿。而这些数据,如个人收入、负债、银行流水、还款历史、等信息都在银行体系之中。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}